
Veröffentlicht am 12. Dezember 2025
🚀 Das Wichtigste in Kürze (TL;DR)
- Historischer Meilenstein: Erstes KI-Modell weltweit mit 100% Score im AMY 2025 Mathe-Benchmark.
- Visuelle Magie: Beherrscht „Visual Reasoning“ auf neuem Level – kann z.B. funktionierende Arduino-Simulationen allein anhand eines Fotos programmieren.
- Agenten-Revolution: 98,7% Erfolgsquote bei komplexen Support-Aufgaben (TA 2 Bench) und fehlerfreie Finanzanalysen.
- Sam Altmans Vision: Das Ergebnis des internen „Code Red“ und der Vorbote für den angekündigten „Adult Mode“ (2026).
- Der Haken: Deutlich teurer ($1.75 Input / $14.00 Output) und teils „überqualifiziert“ (scheitert an simplen Spielen, während es komplexe Physik meistert).
Am 12. Dezember 2025 hat OpenAI still und heimlich GPT-5.2 veröffentlicht. Während viele dachten, wir hätten das Plateau der KI-Entwicklung erreicht, beweist dieses Update das Gegenteil. CEO Sam Altman fasst die Tragweite des Releases selbstbewusst zusammen:
„Es ist das klügste allgemein verfügbare Modell der Welt, und es ist besonders gut darin, echte Wissensarbeit zu leisten.“
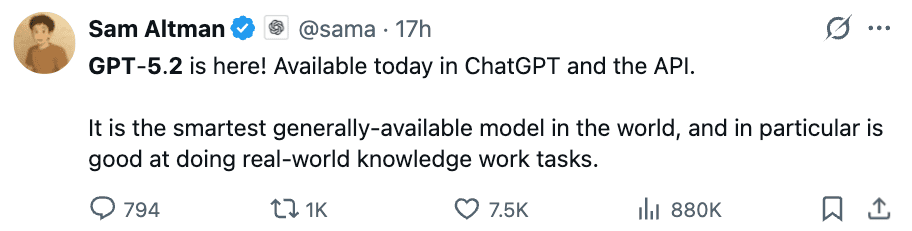
Mit einem perfekten Score in Mathematik und fast surrealen Fähigkeiten im Bereich Physik-Simulation ist GPT-5.2 nicht nur ein kleines Update, sondern ein gewaltiger Sprung in Richtung AGI (Artificial General Intelligence). Das Modell wird von Experten bereits als „direkter Angriff auf Anthropic Claude“ gewertet. Der Knowledge Cutoff (Wissensstand) liegt beim 31. August 2025.
Inhalte
- 1 Die Benchmarks: Ein historischer Moment für KI
- 2 Praxis-Check: Wo GPT-5.2 glänzt (und wo nicht)
- 3 Beispiel-Prompts: Was ist jetzt möglich?
- 4 Was bedeuten diese Benchmarks eigentlich? (Deep Dive)
- 5 Das sagt Sam Altman: „Code Red“ & Die Vision
- 6 Der „Agenten“-Durchbruch & Business Impact
- 7 Preise: Qualität kostet mehr
- 8 Der Vergleich: GPT-5.2 vs. Gemini 3 vs. Claude Opus 4.5
- 9 Fazit: Lohnt sich der Umstieg?
- 10 Häufig gestellte Fragen (FAQ) zu GPT-5.2
- 11 🔗 Quellen & Weiterführende Links
Die Benchmarks: Ein historischer Moment für KI
Das Wichtigste zuerst: Die Zahlen sind beeindruckend. OpenAI hat mit GPT-5.2 in fast allen relevanten Kategorien den Status „State-of-the-Art“ (SOTA) zurückerobert.
Mathematik: Die 100% Marke ist geknackt (AMY 2025)
Im AMY 2025 Benchmark, einem extrem schwierigen Mathematik-Wettbewerb für Hochbegabte, hat GPT-5.2 Geschichte geschrieben. Es erzielte 100%. Es hat jede einzelne Frage korrekt beantwortet.
- GPT-5.2: 100%
- Gemini 3 Pro: 95%
- Claude Opus 4.5: 92.8%

Der AGI-Test (ARC AGI 1 & 2)
Der ARC AGI Benchmark gilt als der „Heilige Gral“, da er echte Intelligenz misst. Hier zeigt sich eine massive Effizienzsteigerung:
- ARC AGI 1: GPT-5.2 Pro erreicht 90.5%.
- Effizienz-Sprung: Vor einem Jahr kostete das Erreichen von 88% noch ca. 4.500 $ pro Task. GPT-5.2 schafft dies nun für nur 11,64 $ – eine Effizienzsteigerung um den Faktor 390.
- ARC AGI 2: Auch im schwierigeren Nachfolger-Test sprang der Score von 17% (GPT-5.1) auf 52.9%.
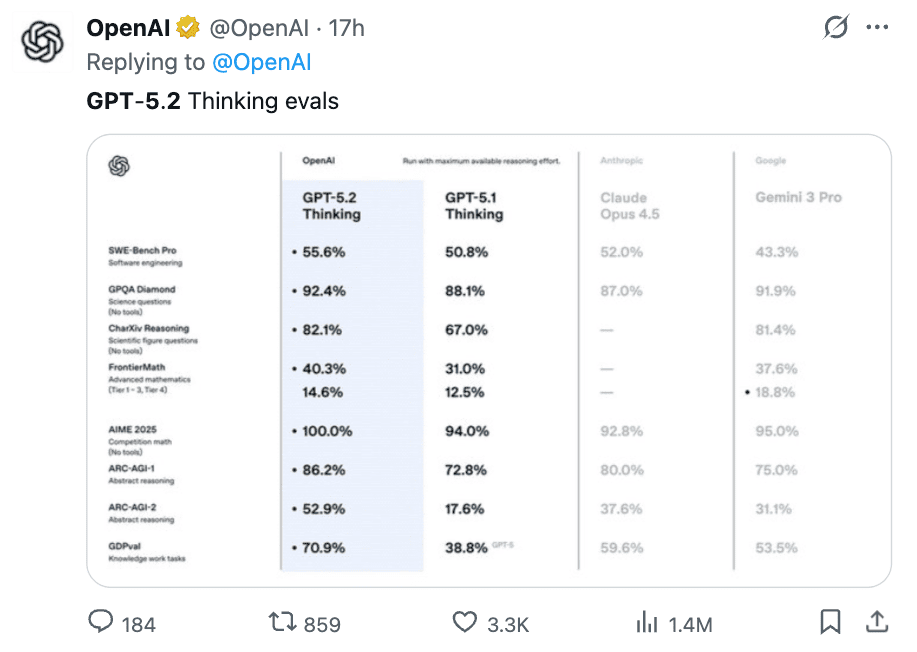
Praxis-Check: Wo GPT-5.2 glänzt (und wo nicht)

Benchmarks sind geduldig. In ersten Hands-On-Tests (u.a. von Tech-Reviewer Bijan Bowen) zeigt sich ein differenziertes Bild aus „magischen Momenten“ und überraschenden Schwächen.
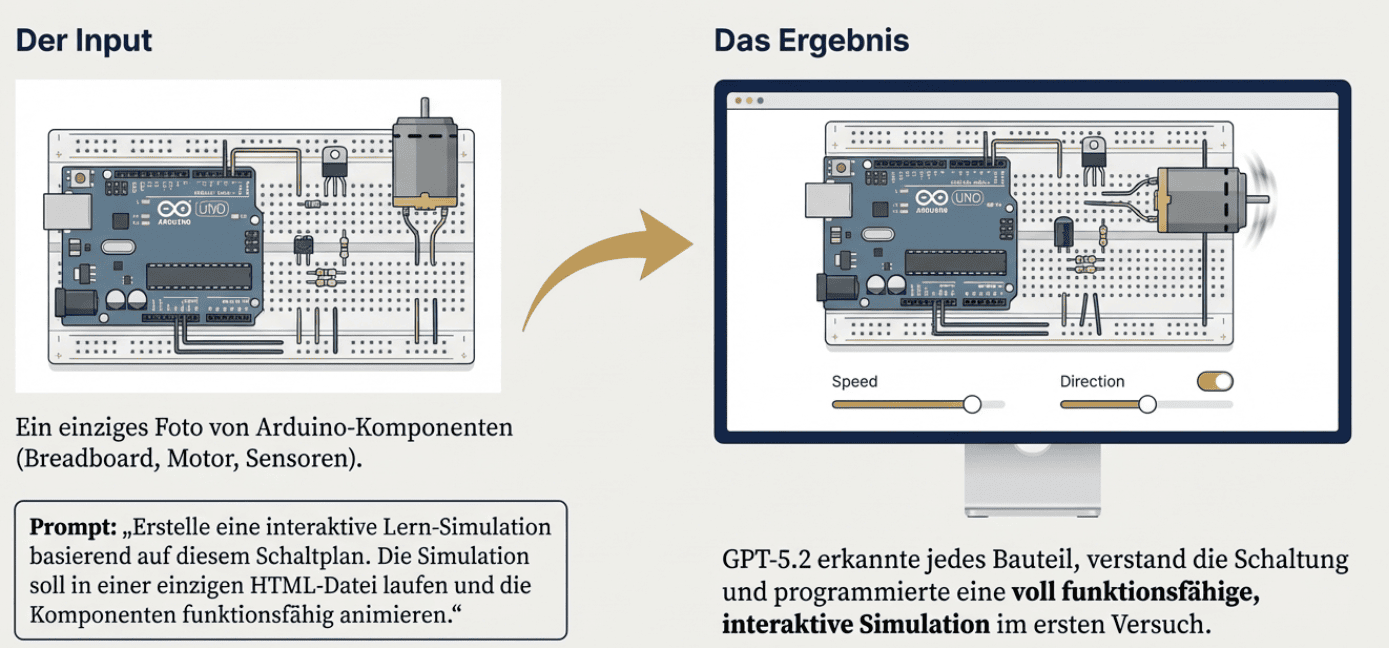
👍 Das Highlight: Arduino-Simulation
Das Modell erhielt lediglich ein Foto von Arduino-Komponenten (Breadboard, Motor, Sensoren). GPT-5.2 erkannte nicht nur jedes Bauteil korrekt, sondern programmierte eine voll funktionsfähige, interaktive Simulation, in der sich der Motor tatsächlich dreht. Ein Paradebeispiel für visuelles Verständnis.
👎 Der Flop: Python FPS Game
Beim Versuch, einen einfachen First-Person-Shooter in Python zu programmieren, scheiterte die Standard-Version („Thinking Standard“) kläglich. Erst mit der Einstellung „Heavy Thinking“ gelang ein Ergebnis. Hier zeigt sich: Mehr Intelligenz bedeutet nicht immer, dass einfache Aufgaben beim ersten Versuch sitzen.
Das „Browser OS“ Phänomen
Ein weiteres Highlight der ersten Tests war ein simuliertes Betriebssystem im Browser. GPT-5.2 baute nicht nur die grafische Oberfläche (inklusive funktionierendem Dark Mode), sondern verstand den Kontext so gut, dass ein Klick auf „Browser öffnen“ innerhalb der Simulation tatsächlich Wikipedia aufrief. Die Vernetzung von Anwendungen („Cross-referencing“) funktioniert deutlich besser als zuvor.
Beispiel-Prompts: Was ist jetzt möglich?
Theorie ist gut, Praxis ist besser. Hier sind drei Prompts, die mit GPT-5.1 oft scheiterten, aber mit GPT-5.2 beeindruckende Ergebnisse liefern.
🧪 Der Physik-Simulator (3D & Visual Reasoning)
Prompt:
Ergebnis: Eine flüssige Simulation mit korrekter Impulserhaltung und Beleuchtung im ersten Versuch („Single Shot“).
Das hier ist in meinem persönlichen Test herausgekommen:
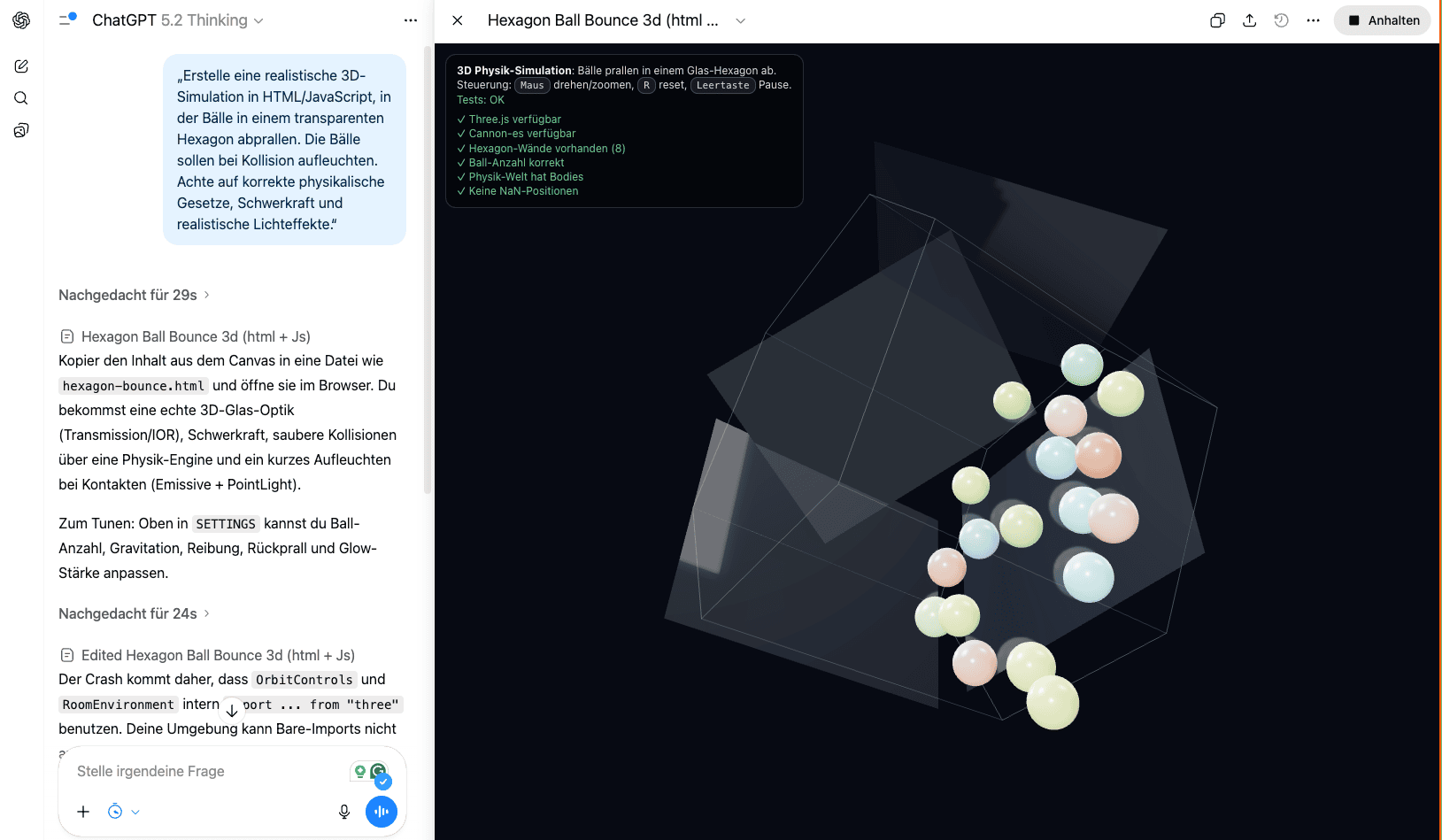
🌊 Die One-File-App (Interaktive Simulationen)
Prompt:
Ergebnis: Im Direktvergleich wirkt die Version von GPT-5.1 wie „Windows 98“, während GPT-5.2 eine visuell beeindruckende „Windows 7“-Ästhetik liefert.
📊 Der Investment-Banker (Fehlerfreie Finanzen)
Prompt:
Ergebnis: Mathematische Beziehungen zwischen den Finanzierungsrunden werden korrekt erkannt und fehlerfrei berechnet.
⚡ Die Arduino-Challenge (Visual Reasoning)
Prompt (mit Bild-Upload):
Ergebnis: Fehlerfreie Erkennung der Hardware (Stepper Motor, Driver Board) und funktionierender Code.
Was bedeuten diese Benchmarks eigentlich? (Deep Dive)
🧪 GPQA Diamond (Wissenschaft)
Dies sind „Google-Proof“ Fragen auf Doktoranden-Niveau in Biologie, Physik und Chemie. Selbst Experten tun sich hier schwer. GPT-5.2 verbessert sich hier von 88.1% auf 92.4%.
💻 Swebench Pro (Coding)
Dieser Test prüft, ob eine KI echte GitHub-Issues (Software-Fehler) in Open-Source-Projekten lösen kann. GPT-5.2 erreicht hier 55.6% (zuvor 50.8%).
Das sagt Sam Altman: „Code Red“ & Die Vision
Hinter den Kulissen herrschte bei OpenAI offenbar Hochdruck. Berichten zufolge rief CEO Sam Altman Anfang Dezember einen internen „Code Red“ aus, um auf den Release von Googles Gemini 3 zu reagieren. Die Strategie scheint aufgegangen zu sein.
Altman verbindet mit GPT-5.2 zwei große Versprechen für die Zukunft:
- Das „Intelligence Age“: Er bekräftigte seine Vision, dass wir nur noch „ein paar tausend Tage“ von einer Superintelligenz entfernt sind. GPT-5.2 sei ein entscheidender Schritt, um KI von einem Chatbot zu einem echten Mitarbeiter zu entwickeln.
- „Adult Mode“ (2026): Auf X bestätigte er zudem Pläne für das nächste Jahr. Anfang 2026 soll ein Modus eingeführt werden, der „erwachsene Nutzer wie Erwachsene behandelt“ („treat adult users like adults“). Das deutet auf weniger strikte Zensurfilter für volljährige Nutzer hin.
Der „Agenten“-Durchbruch & Business Impact
Vielleicht die wichtigste Nachricht für Unternehmen: Laut Matt Shumer hat sich die Leistung bei „ökonomisch wertvollen Aufgaben“ (Real World Tasks) fast verdoppelt.
Im TA 2 Benchmark (Kundensupport/Agenten) springt die Erfolgsrate von 47% auf 98.7%. Das bedeutet: Die Fähigkeit der KI, komplexe Arbeitsabläufe autonom durchzuführen, ist nun auf einem Level, das echte Automatisierung ermöglicht.
Kontext & „Needle in a Haystack“
Das Kontext-Fenster bleibt bei stabilen 256.000 Tokens. Aber die Nutzung dieses Speicherplatzes ist viel präziser geworden. Im „Needle in a Haystack“-Test (das Finden einer winzigen Info in riesigen Textmengen) zeigt GPT-5.2 auch bei komplexen Anfragen eine fast perfekte Rückrufquote von 98%.
Preise: Qualität kostet mehr
Die gesteigerte Intelligenz hat ihren Preis. OpenAI hat die API-Kosten angehoben:
Die neuen Preise (pro 1 Million Tokens):
- Input: $1.75 (vorher $1.25)
- Output: $14.00 (vorher $10.00)
Der Vergleich: GPT-5.2 vs. Gemini 3 vs. Claude Opus 4.5
Wie schlägt sich das neue Modell im direkten Vergleich mit den Giganten von Google und Anthropic? Hier ist der Überblick für Ende 2025:
| Feature | OpenAI GPT-5.2 | Google Gemini 3 Pro | Claude Opus 4.5 |
|---|---|---|---|
| Mathe (AMY 2025) | 100% 🏆 | 95% | 92.8% |
| Coding (Swebench Pro) | 55.6% 🏆 | ~51% | ~49% |
| Kontext-Fenster | 256k Tokens | 2M+ Tokens 🏆 | 500k Tokens |
| Stärke | Physik, Agenten, Mathe | Multimodalität, Video | Kreatives Schreiben |
Fazit: Lohnt sich der Umstieg?
GPT-5.2 behebt die größten Schwachstellen der KI: Es kann endlich verlässlich rechnen (100% AMY), es „versteht“ Physik und es agiert fast fehlerfrei als Agent. Während Gemini 3 beim riesigen Kontextfenster die Nase vorn hat und Claude Opus weiterhin für viele Autoren der Favorit bleibt, ist GPT-5.2 die neue unangefochtene Nummer 1 für Entwickler, Wissenschaftler und Business-Anwendungen.
Häufig gestellte Fragen (FAQ) zu GPT-5.2
❓ Wann wurde GPT-5.2 veröffentlicht?
GPT-5.2 wurde am 12. Dezember 2025 von OpenAI veröffentlicht. Es ist sofort für zahlende Nutzer (ChatGPT Plus, Team, Enterprise) verfügbar.
❓ Ist GPT-5.2 besser als Gemini 3 und Claude Opus 4.5?
In den Bereichen Mathematik (100% Score) und Coding (Swebench Pro) ist GPT-5.2 derzeit das leistungsstärkste Modell der Welt. Für Aufgaben, die extrem große Datenmengen (über 256k Token) erfordern, ist Google Gemini 3 jedoch weiterhin führend.
❓ Was kostet die GPT-5.2 API?
Die Preise sind gestiegen: 1 Million Input-Tokens kosten $1.75, 1 Million Output-Tokens kosten $14.00. Damit positioniert sich GPT-5.2 als Premium-Modell für professionelle Anwendungen.
❓ Gibt es eine kostenlose Version von GPT-5.2?
Aktuell ist GPT-5.2 nur für zahlende Abonnenten verfügbar. Nutzer der kostenlosen Version von ChatGPT nutzen weiterhin das effizientere GPT-4o-mini oder GPT-5.1-Flash Modell.
🔗 Quellen & Weiterführende Links
Um tiefer in die Materie einzutauchen, empfehlen wir die folgenden Originalquellen und Reviews, die für diesen Artikel analysiert wurden:
- 🏢 OpenAI (Offiziell):
„Introducing GPT-5.2“ – Offizieller Blog PostDie offizielle Ankündigung mit allen technischen Details, Benchmarks und Release-Notes. - 📰 TechRadar (Review):
„GPT-5.2 Hands-On: The new king of coding?“Unabhängige journalistische Einordnung der neuen Features im Vergleich zur Konkurrenz. - 📺 Matthew Berman (YouTube):
„OpenAI just dropped GPT-5.2… (WOAH)“Detaillierte Analyse der Benchmarks und Business-Use-Cases. - 📺 Bijan Bowen (YouTube):
„GPT-5.2 Hands-On Testing – Is THIS OpenAI’s Best Model?“Hands-on Test des Arduino-Simulators und Gaming-Fähigkeiten. - 🐦 Sam Altman auf X:
Statement zum „Intelligence Age“ & Code Red - 🌐 ARC Prize (Offiziell):
ARC AGI Benchmark InformationenHintergrundinfos zum härtesten IQ-Test für KIs.
Normalerweise bleibe ich 1 bis 3 Monate an einem Ort, aber mein langfristiger Plan ist es, mich an einigen wenigen Orten niederzulassen, an denen es mir am besten gefällt. Neben dieser Webseiten betreibe ich zahlreiche Nischenseiten und einen Youtube-Kanal.
Seit 2021 habe ich die transformative Kraft der künstlichen Intelligenz (KI) für mich entdeckt und seitdem über 50 KI-Tools intensiv getestet und nutze diese täglich. Diese fortschrittlichen Werkzeuge spielen eine zentrale Rolle in meiner täglichen Arbeit, indem sie mir helfen, SEO-Strategien und Online-Marketing-Kampagnen zu optimieren. Meine Stärke liegt darin, KI-Technologien effektiv für innovative Lösungen einzusetzen.
Lerne mehr über mich auf meiner ausführlichen "Über mich"-Seite
- AV-Depot Rechner - 31. März 2026
- Google Spam Update März 2026: Traffic-Absturz? Was du jetzt tun musst (und was nicht) - 26. März 2026
- Claude Code 2.0 im Test: Zerstört dieses Update das alte ChatGPT endgültig? - 18. März 2026